大数据 2022 年 1 月 3 日
Flink入门
对Flink中的一些基本概念进行介绍
Flink入门
简介
Apache _Flink_是由Apache软件基金会开发的开源流处理框架,其核心是用Java和Scala编写的分布式流数据流引擎。Flink以数据并行和流水线方式执行任意流数据程序,Flink的流水线运行时系统可以执行批处理和流处理程序。
架构
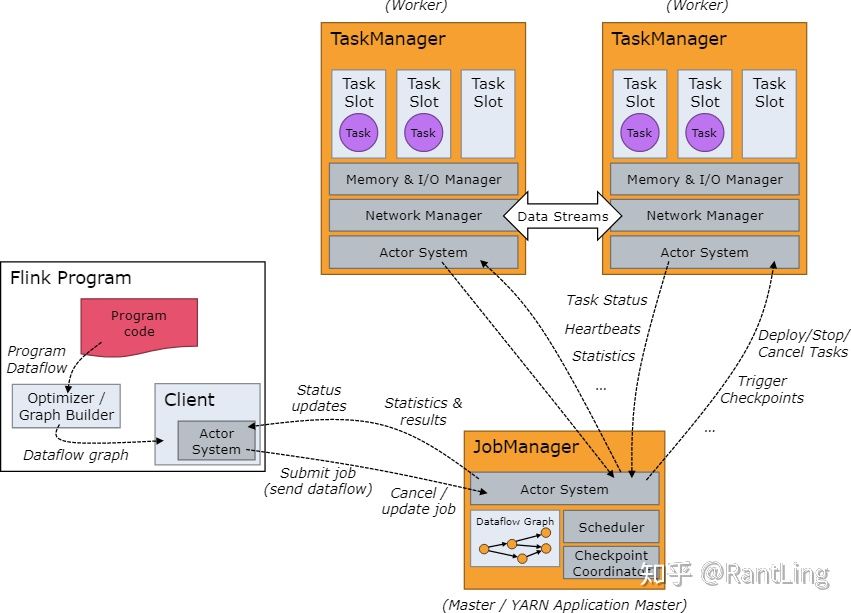
Flink架构图
- JobManager*:*主要负责调度task,协调checkpoint进行错误恢复等。当客户端将打包好的任务提交到JobManager之后,JobManager就会根据注册的TaskManager资源信息将任务分配给有资源的TaskManager,然后启动运行任务。TaskManger从JobManager获取task信息,然后使用slot资源运行task;
- TaskManager:执行数据流的task,一个task通过设置并行度,可能会有多个subtask。 每个TaskManager都是作为一个独立的JVM进程运行的。他主要负责在独立的线程执行的operator。其中能执行多少个operator取决于每个taskManager指定的slots数量。Task slot是Flink中最小的资源单位。假如一个taskManager有3个slot,他就会给每个slot分配1/3的内存资源,目前slot不会对cpu进行隔离。同一个taskManager中的slot会共享网络资源和心跳信息。
数据
有界数据流
有界数据流就是指输入的数据有始有终。例如数据可能是一分钟或者一天的交易数据等等。处理这种有界数据流的方式也被称之为批处理。
无界数据流
无界数据流就是指有始无终的数据,数据一旦开始生成就会持续不断的产生新的数据,即数据没有时间边界。无界数据流需要持续不断地处理。
编程模型
在Flink,编程模型的抽象层级主要分为以下4种,越往下抽象度越低,编程越复杂,灵活度越高。
.jpeg)
Flink编程模型
这4层中,一般用于开发的是第三层,即
DataStrem/DataSetAPI。用户可以使用DataStream API处理无界数据流,使用DataSet API处理有界数据流。同时这两个API都提供了各种各样的接口来处理数据。例如常见的map、filter、flatMap等等,而且支持python,scala,java等编程语言。程序结构
Flink常用api
Data Source
数据来源
-
基于集合
- fromCollection(Collection) - 从 Java 的 Java.util.Collection 创建数据流。集合中的所有元素类型必须相同。
- fromCollection(Iterator, Class) - 从一个迭代器中创建数据流。Class 指定了该迭代器返回元素的类型。
- fromElements(T …) - 从给定的对象序列中创建数据流。所有对象类型必须相同。
- fromParallelCollection(SplittableIterator, Class) - 从一个迭代器中创建并行数据流。Class 指定了该迭代器返回元素的类型。
- generateSequence(from, to) - 创建一个生成指定区间范围内的数字序列的并行数据流。
-
基于文件
- readTextFile(path) - 读取文本文件,即符合 TextInputFormat 规范的文件,并将其作为字符串返回。
- readFile(fileInputFormat, path) - 根据指定的文件输入格式读取文件(一次)。
- readFile(fileInputFormat, path, watchType, interval, pathFilter, typeInfo) - 这是上面两个方法内部调用的方法。它根据给定的 fileInputFormat 和读取路径读取文件。根据提供的 watchType,这个 source 可以定期(每隔 interval 毫秒)监测给定路径的新数据(FileProcessingMode.PROCESS_CONTINUOUSLY),或者处理一次路径对应文件的数据并退出(FileProcessingMode.PROCESS_ONCE)。你可以通过 pathFilter 进一步排除掉需要处理的文件。
-
基于Socket
socketTextStream(String hostname, int port) - 从 socket 读取。元素可以用分隔符切分。
-
自定义
addSource - 添加一个新的 source function。
Data Transformation
数据转换
Map
这是最简单的转换之一,其中输入是一个数据流,输出的也是一个数据流
SingleOutputStreamOperator<Student> map = student.map(new MapFunction<Student, Student>() {
@Override
public Student map(Student value) throws Exception {
Student s1 = new Student();
s1.id = value.id;
s1.name = value.name;
s1.password = value.password;
s1.age = value.age + 5;
return s1;
}
});
map.print();将每个人的年龄都增加 5 岁
FlatMap
采用一条记录并输出零个,一个或多个记录。
SingleOutputStreamOperator<Student> flatMap = student.flatMap(new FlatMapFunction<Student, Student>() {
@Override
public void flatMap(Student value, Collector<Student> out) throws Exception {
if (value.id % 2 == 0) {
out.collect(value);
}
}
});
flatMap.print();这里将 id 为偶数的聚集出来。
Filter
函数根据条件判断出结果。
SingleOutputStreamOperator<Student> filter = student.filter(new FilterFunction<Student>() {
@Override
public boolean filter(Student value) throws Exception {
if (value.id > 95) {
return true;
}
return false;
}
});
filter.print();这里将 id 大于 95 的过滤出来,然后打印出来。
KeyBy
在逻辑上是基于 key 对流进行分区。在内部,它使用 hash 函数对流进行分区。它返回 KeyedDataStream 数据流。
KeyedStream<Student, Integer> keyBy = student.keyBy(new KeySelector<Student, Integer>() {
@Override
public Integer getKey(Student value) throws Exception {
return value.age;
}
});
keyBy.print();对 student 的 age 做 KeyBy 操作分区
Reduce
返回单个的结果值,并且 reduce 操作每处理一个元素总是创建一个新值。常用的方法有 average, sum, min, max, count,使用 reduce 方法都可实现。
SingleOutputStreamOperator<Student> reduce = student.keyBy(new KeySelector<Student, Integer>() {
@Override
public Integer getKey(Student value) throws Exception {
return value.age;
}
}).reduce(new ReduceFunction<Student>() {
@Override
public Student reduce(Student value1, Student value2) throws Exception {
Student student1 = new Student();
student1.name = value1.name + value2.name;
student1.id = (value1.id + value2.id) / 2;
student1.password = value1.password + value2.password;
student1.age = (value1.age + value2.age) / 2;
return student1;
}
});
reduce.print();先将数据流进行 keyby 操作,因为执行 reduce 操作只能是 KeyedStream,然后将 student 对象的 age 做了一个求平均值的操作
Fold
将数据流的每一次输出进行滚动叠加
SingleOutputStreamOperator<String> result = keyedStream.fold("同学:", new FoldFunction<Tuple3<String, String, Integer>, String>() {
@Override
public String fold(String s, Tuple3<String, String, Integer> tuple3) throws Exception {
if (s.startsWith("男") || s.startsWith("女")){
return s + tuple3.f0 + "、";
} else {
return (tuple3.f1.equals("man") ? "男" : "女") + s + tuple3.f0 + "、";
}
}
});
result.print();按性别分区,按排序,未位追加输出
Aggregations DataStream
API 支持各种聚合,例如 min,max,sum 等。 这些函数可以应用于 KeyedStream 以获得 Aggregations 聚合。
KeyedStream.sum(0)
KeyedStream.sum("key")
KeyedStream.min(0)
KeyedStream.min("key")
KeyedStream.max(0)
KeyedStream.max("key")
KeyedStream.minBy(0)
KeyedStream.minBy("key")
KeyedStream.maxBy(0)
KeyedStream.maxBy("key")max 和 maxBy 之间的区别在于 max 返回流中的最大值,但 maxBy 返回具有最大值的键, min 和 minBy 同理。
Window
通常来讲,Window 就是用来对一个无限的流设置一个有限的集合,在有界的数据集上进行操作的一种机制。window 又可以分为基于时间(Time-based)的 window 以及基于数量(Count-based)的 window。
####### Time Windows
正如命名那样,Time Windows 根据时间来聚合流数据。例如:一分钟的 tumbling time window 收集一分钟的元素,并在一分钟过后对窗口中的所有元素应用于一个函数。
在 Flink 中定义 tumbling time windows(翻滚时间窗口) 和 sliding time windows(滑动时间窗口) 非常简单:
tumbling time windows(翻滚时间窗口)
data.keyBy(1)
.timeWindow(Time.minutes(1)) //tumbling time window 每分钟统计一次数量和
.sum(1);sliding time windows(滑动时间窗口)
data.keyBy(1)
.timeWindow(Time.minutes(1), Time.seconds(30)) //sliding time window 每隔 30s 统计过去一分钟的数量和
.sum(1);Count Windows
Apache Flink 还提供计数窗口功能。如果计数窗口设置的为 100 ,那么将会在窗口中收集 100 个事件,并在添加第 100 个元素时计算窗口的值。
在 Flink 的 DataStream API 中,tumbling count window 和 sliding count window 的定义如下:
tumbling count window
data.keyBy(1)
.countWindow(100) //统计每 100 个元素的数量之和
.sum(1);sliding count window
data.keyBy(1)
.countWindow(100, 10) //每 10 个元素统计过去 100 个元素的数量之和
.sum(1);Union
函数将两个或多个数据流结合在一起。 这样就可以并行地组合数据流。
inputStream.union(inputStream1, inputStream2, ...);Window join
我们可以通过一些 key 将同一个 window 的两个数据流 join 起来。
inputStream.join(inputStream1)
.where(0).equalTo(1)
.window(Time.seconds(5))
.apply (new JoinFunction () {...});在 5 秒的窗口中连接两个流,其中第一个流的第一个属性的连接条件等于另一个流的第二个属性。
Split
根据条件将流拆分为两个或多个流。
SplitStream<Integer> split = inputStream.split(new OutputSelector<Integer>() {
@Override
public Iterable<String> select(Integer value) {
List<String> output = new ArrayList<String>();
if (value % 2 == 0) {
output.add("even");
}
else {
output.add("odd");
}
return output;
}
});Select
从拆分流中选择特定流。
SplitStream<Integer> split;
DataStream<Integer> even = split.select("even");
DataStream<Integer> odd = split.select("odd");
DataStream<Integer> all = split.select("even","odd");Project
从事件流中选择属性子集,并仅将所选元素发送到下一个处理流。
DataStream<Tuple4<Integer, Double, String, String>> in = // [...]
DataStream<Tuple2<String, String>> out = in.project(3,2);从给定记录中选择属性号 2 和 3
Data Sink
数据存储
-
原生支持
Kafka、ElasticSearch、Socket、RabbitMQ、JDBC、Cassandra POJO、File、Print
-
自定义
继承 RichSinkFunction 抽象类,重写 invoke 方法
版权声明:自由转载-非商用-非衍生-保持署名(创意共享3.0许可证)
作者: OnlyWaitY 发表日期:2022 年 1 月 3 日